Software Development in New York: Benefits, Use Cases, Process & Cost Explained
- Ali Hasan

Contents
The question “what is machine learning” is one that shapes modern discussions around technology, innovation, and the future of work. Machine Learning (ML), a branch of Artificial Intelligence (AI), focuses on creating systems that can learn from and make decisions based on data without being explicitly programmed for every specific task.
From voice assistants like Siri to medical image analysis tools, Machine Learning applications are deeply woven into the fabric of our daily lives. In this blog, we’ll explore the basics of ML, its connection to AI and Deep Learning, and how they differ from each other — providing a solid foundation for beginners and tech-curious professionals alike.
Introduction to Machine Learning:
Understanding what machine learning is starts with recognizing its fundamental approach: enabling computers to learn automatically from past experiences or data inputs.
Instead of traditional rule-based programming, ML relies on algorithms that identify patterns, adjust to new information, and make informed decisions. These models improve their performance over time as they are exposed to more data.
Key Concepts:
- Algorithms: Structured sets of rules for processing data and making predictions.
- Model Training: The process of feeding historical data into algorithms to help them learn patterns.
- Data Preparation: Cleaning and organizing data to make it usable for models.
- Supervised vs Unsupervised Learning: Primary learning approaches depending on labeled or unlabeled data availability.
A Brief Evolution of Machine Learning:
The concept of machines learning from experience dates back to the 1950s. Alan Turing’s seminal question, “Can machines think?” sparked early discussions. In 1959, Arthur Samuel built a checkers-playing program that improved by playing against itself — a true milestone in machine learning history.
Since then, ML has evolved from simple pattern recognition systems to today’s complex deep learning models that can drive cars, compose music, and even assist in surgical procedures.
Why is Machine Learning Important Today?
- Data Explosion: With digital transformation, businesses generate petabytes of data daily. ML helps extract actionable insights.
- Scalability: ML models can analyze enormous datasets beyond human capability.
- Real-Time Decision Making: Systems like fraud detection or autonomous vehicles require decisions within milliseconds.
- Continuous Improvement: Unlike static software, ML models evolve and refine themselves over time.
In short, understanding what machine learning is has become essential for anyone navigating the modern digital landscape.
What is Artificial Intelligence (AI)?
To fully grasp machine learning, one must first understand Artificial Intelligence (AI) — the broader domain under which ML operates.
Artificial Intelligence is the science and engineering of making machines capable of performing tasks that typically require human intelligence. These tasks include reasoning, learning, problem-solving, perception, and even understanding language.
Categories of Artificial Intelligence:
- Narrow AI: Designed for specific tasks (e.g., facial recognition, translation apps).
- General AI: Hypothetical systems with human-like cognitive abilities across any domain.
- Super AI: A theoretical level where AI surpasses human intelligence (still fictional at this stage).
Components of Artificial Intelligence:
- Machine Learning: Enabling systems to learn patterns from data.
- Expert Systems: Using pre-defined rules and logic for decision-making.
- Natural Language Processing (NLP): Understanding and generating human language.
- Computer Vision: Interpreting and analyzing visual information.
Real-World Examples of Artificial Intelligence:
- Healthcare: IBM Watson assisting doctors in diagnosing cancer.
- Finance: AI-based systems analyzing stock market trends.
- Transportation: Smart traffic management using AI-driven data insights.
IBM reports that 35% of companies are currently using AI, and 42% are exploring AI technologies. AI represents the dream of machines behaving intelligently, with machine learning being one of the most practical and successful approaches toward achieving that dream.
Looking to Multiply Your ROI Through SaaS Product Development?
Let's Talk
We are offering 50% reduced costs for SaaS Product Development for new clients. If you are looking to invest less and earn more, we are your go-to partners!
What is Deep Learning (DL)?
While understanding what is machine learning is crucial, it’s equally important to delve into Deep Learning (DL) — a transformative subset of ML.
Deep Learning leverages artificial neural networks, structures modeled loosely after the human brain. These networks consist of layers of interconnected “neurons” that process input data, progressively learning more abstract representations at each layer.
Key Features of Deep Learning:
- Automatic Feature Extraction: Unlike traditional ML, no need for manual feature engineering.
- Layered Learning: Deep neural networks can have dozens or even hundreds of layers, each learning increasingly complex features.
- Data Hungry: DL models often require massive labeled datasets and significant computational resources (like GPUs).
Major Architectures:
- Convolutional Neural Networks (CNNs): Specialized for image recognition and processing tasks.
- Recurrent Neural Networks (RNNs): Excellent for sequence-based data like time series or natural language.
How Deep Learning Works:
- Input Layer: Raw data such as images, text, or audio enters the network.
- Hidden Layers: Multiple transformations and feature extractions happen through mathematical functions.
- Output Layer: Produces predictions or classifications based on learned features.
Deep Learning has fueled groundbreaking advancements like real-time language translation, autonomous driving, and medical imaging diagnostics.
Read More Related Blogs:
Differences Between ML, DL, and AI:
Although closely related, Artificial Intelligence, Machine Learning, and Deep Learning are distinct concepts.
Here’s a detailed side-by-side comparison:
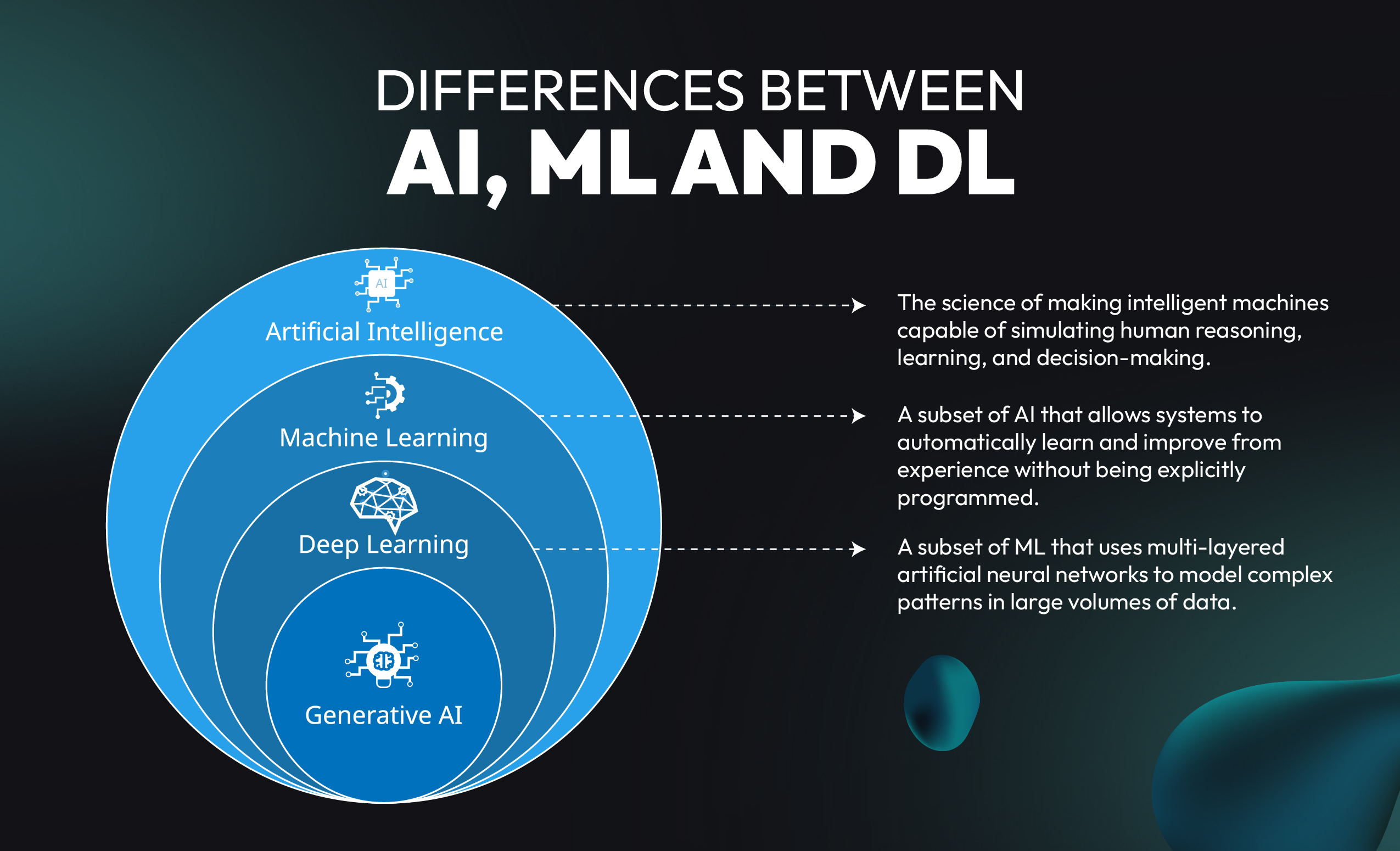
| Aspect | Artificial Intelligence (AI) | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|---|
| Definition | Creating intelligent machines to perform tasks | Training machines to learn from data | Training machines using multi-layered neural networks |
| Scope | Broad, covering reasoning, planning, learning | Focused on data-driven prediction and decision-making | Focused on hierarchical learning with minimal human intervention |
| Data Dependency | Moderate | Requires structured/labeled datasets | Requires vast labeled datasets |
| Human Intervention | Often high (especially for expert systems) | Medium (model building, feature selection) | Low (automatic feature extraction) |
| Examples | Chess-playing programs, robotic process automation | Spam email filtering, product recommendations | Voice assistants, facial recognition in security systems |
Real-World Examples:
- AI Example: An AI system helping pilots with navigation by integrating multiple data streams.
- ML Example: Netflix recommending movies based on viewing history patterns.
- DL Example: Tesla’s autonomous vehicles recognizing pedestrians, traffic signs, and obstacles in real time.
In essence:
- AI is the goal.
- ML is the method.
- DL is a powerful technique within ML.
Understanding the difference ensures clarity when navigating the world of modern intelligent systems.
Types of Machine Learning:
After understanding what is machine learning, the next essential step is to explore the different types of machine learning. Each type has its own learning method, strengths, challenges, and ideal use cases. Broadly, Machine Learning is categorized into four main types:
- Supervised Learning
- Unsupervised Learning
- Semi-supervised Learning
- Reinforcement Learning
Let’s dive deep into each category and understand how machines learn in various environments.

1- Supervised Learning:
Supervised Learning is the most widely used and the most intuitive form of Machine Learning. In this approach, the model is trained on a labeled dataset, meaning that each input data point is paired with the correct output.
Essentially, the algorithm learns by example. The goal is to create a function that can map inputs to desired outputs accurately.
- Input Data: Data is provided with correct labels.
- Training Phase: The model makes predictions and is corrected based on errors.
- Testing Phase: Model performance is evaluated on new, unseen data.
- Linear Regression: Predicting continuous values (e.g., housing prices).
- Logistic Regression: Binary classification (e.g., email spam detection).
- Decision Trees: Making decisions based on feature values.
- Support Vector Machines (SVMs): Finding hyperplanes to separate classes.
- Healthcare: Diagnosing diseases based on symptoms and medical images.
- Finance: Predicting creditworthiness for loan approvals.
- Retail: Customer churn prediction based on shopping behavior.
- High accuracy when trained with quality labeled data.
- Clear interpretability in many algorithms like decision trees.
- Data Labeling: Manually labeling large datasets is time-consuming and costly.
- Overfitting: Models can sometimes memorize the training data instead of learning generalizable patterns.
In the supervised approach, the emphasis is on learning a mapping from inputs to outputs, making it extremely powerful for predictive tasks.
2- Unsupervised Learning:
Unsupervised Learning is quite different from supervised learning. In this case, the model works with unlabeled data. There is no guidance in the form of correct outputs. Instead, the algorithm must discover the hidden structure or patterns in the data on its own.
Think of it as trying to find meaningful groups or representations in data without being told what to look for.
- Input Data: Only input features, no labels provided.
- Pattern Discovery: The algorithm looks for similarities or anomalies.
- Groupings or Representations: Results in clusters or new feature spaces.
- K-Means Clustering: Grouping similar data points together.
- Hierarchical Clustering: Building tree-like structures of groups.
- Principal Component Analysis (PCA): Reducing data dimensionality for easier analysis.
- Customer Segmentation: Identifying customer groups based on purchasing behavior.
- Anomaly Detection: Finding unusual patterns in network security or banking transactions.
- Market Basket Analysis: Understanding purchase patterns in retail.
- Can work with raw, unlabeled data.
- Useful for exploratory data analysis and discovering hidden relationships.
- Hard to evaluate results objectively.
- No absolute “right answer” — clustering can be subjective.
Unsupervised machine learning plays a vital role where labeled data is unavailable but discovering structure within data is valuable for business insights.
3- Semi-supervised Learning:
Semi-supervised Learning falls between supervised and unsupervised learning. It uses a small amount of labeled data and a large amount of unlabeled data for training.
The idea is that the model can learn the underlying structure from the unlabeled data and refine its predictions using the limited labeled examples.
- Small Labeled Dataset: Guides the model initially.
- Large Unlabeled Dataset: Helps the model generalize and uncover additional patterns.
- Iterative Improvement: The model improves its learning progressively.
- Self-training Algorithms: Model labels the unlabeled data itself in iterations.
- Graph-based Models: Represent data as a graph and spread labels across similar nodes.
- Speech Recognition: Annotating a small sample of speech clips and letting the model learn from vast unlabeled audio data.
- Web Content Classification: Categorizing vast amounts of online content using few labeled examples.
- Medical Research: Labeling a small portion of medical scans while the model extrapolates to millions of images.
- Reduces the cost and effort of manual labeling.
- Achieves better performance than purely unsupervised learning.
- If the small labeled set is biased, the model might learn wrong patterns.
- Complex to design optimal training workflows.
Semi-supervised learning bridges the gap between the need for large labeled datasets and the practical challenges of labeling real-world data.
4- Reinforcement Learning:
Reinforcement Learning (RL) is a completely different approach compared to the previous types. In RL, an agent learns to perform a task by interacting with an environment and receiving rewards or penalties based on its actions.
The agent’s goal is to maximize cumulative rewards over time.
- Agent: The decision-maker.
- Environment: The setting or context in which the agent operates.
- Actions: Choices the agent can make.
- Rewards: Feedback received after performing actions.
- Exploration: Trying new actions to discover their effects.
- Exploitation: Using known actions that yield the highest rewards.
- Policy: The strategy that the agent develops over time.
- Q-Learning: Learning the value of taking an action in a particular state.
- Deep Q Networks (DQNs): Combining reinforcement learning with deep learning.
- Policy Gradient Methods: Directly optimizing the agent’s decision-making policy.
- Game Playing: AlphaGo beating human champions in the game of Go.
- Robotics: Teaching robots to walk or pick objects.
- Finance: Developing strategies for algorithmic trading.
- Learn complex behaviors without requiring labeled datasets.
- Continually improves performance based on direct feedback.
- Training can be very time-consuming.
- Poor exploration strategies may lead to suboptimal performance.
Reinforcement learning mimics the way humans and animals learn from trial and error, making it an exciting and powerful frontier in machine learning and deep learning.
Understanding the types of machine learning — supervised, unsupervised, semi-supervised, and reinforcement learning — gives a clear picture of how diverse and powerful the field is. Each type has its ideal use case, strengths, and limitations, making them suitable for different real-world problems.
Whether training a fraud detection model with supervised learning, uncovering customer groups using unsupervised learning, or teaching an autonomous robot to navigate through reinforcement learning, these paradigms form the backbone of modern intelligent systems.
When exploring what machine learning is, appreciating these learning types equips you with the foundational knowledge needed to navigate this fascinating field confidently.
Hire the Right NYC Software Company Without Wasting Weeks on Research
Let's Talk
Built for decision-makers who need fast, proven results—this custom match saves you time, cuts risk, and gets your project moving.
How Machine Learning Works:
Now that we understand what is machine learning and its various types, it’s time to explore how machine learning works behind the scenes. Building a successful ML model is not a single action — it’s a systematic process involving multiple critical stages, each with its own best practices and challenges.
From collecting the right data to training, tuning, and finally deploying a model, each step ensures that the machine can learn effectively and deliver accurate results in real-world applications.

1- Data Collection:
The first and arguably the most crucial step in building a machine learning model is data collection. High-quality data is the fuel that powers machine learning algorithms.
- Defining Objectives: What problem are we solving?
- Identifying Data Sources: Internal databases, public datasets, IoT devices, APIs, web scraping, etc.
- Data Acquisition: Gathering structured or unstructured data relevant to the problem.
- Volume and Variety: Ensuring enough examples and diverse conditions are represented.
Without a sufficient amount of representative data, even the most advanced algorithms will fail to generalize effectively. Poor data collection leads to biased models and inaccurate predictions.
A facial recognition model must be trained on a wide variety of faces across different lighting conditions, ethnicities, and expressions to function accurately across global users.
2- Data Processing:
Raw data is often messy, incomplete, or inconsistent. Data processing, or data preparation, ensures that the input data is clean, structured, and ready for model training.
- Cleaning: Handling missing values, correcting errors, removing duplicates.
- Normalization and Scaling: Standardizing data to bring all features to a similar scale.
- Encoding Categorical Data: Converting text labels into numerical form for algorithms.
- Data Augmentation: In tasks like image classification, artificially enlarging datasets through techniques like rotation or flipping.
Garbage in, garbage out. If you feed a machine learning model with low-quality data, it will inevitably produce poor predictions.
In predicting housing prices, missing values for property size or location must be filled in or imputed logically to ensure the model receives complete information.
3- Model Selection:
Once the data is ready, the next step is selecting the appropriate model. Different machine learning algorithms are suited to different types of problems..
- Nature of the Problem: Is it classification, regression, clustering, or reinforcement?
- Data Size: Larger datasets might favor deep learning approaches; smaller datasets might be better suited to traditional algorithms.
- Accuracy vs Interpretability: Do we need a highly accurate black-box model, or a more interpretable but slightly less accurate model?
- Classification: Decision Trees, Random Forests, Logistic Regression.
- Regression: Linear Regression, Support Vector Regression.
- Clustering: K-Means, DBSCAN.
- Deep Learning: Neural Networks for complex pattern recognition.
4- Model Training:
With the model selected, it’s time for the training phase — where the real learning happens.
- The model is fed training data (inputs and corresponding outputs).
- It makes predictions and compares them to the actual outputs.
- Based on errors (loss), it adjusts its internal parameters to improve.
- Loss Function: Measures how far the model’s predictions are from actual values.
- Optimization Algorithm: Methods like gradient descent help minimize the loss function.
Training a linear regression machine learning model involves adjusting the slope and intercept of a line to minimize prediction errors on a housing dataset.
5- Model Evaluation:
After training, we need to evaluate the model’s performance to ensure it learned useful patterns and not just memorized the training data (overfitting).
- Accuracy: Percentage of correct predictions (classification problems).
- Precision and Recall: Handling imbalanced datasets where false positives/negatives matter.
- F1-Score: Harmonic means of precision and recall.
- Mean Squared Error (MSE): Used for regression tasks to measure prediction error..
- Train/Test Split: Dividing data into separate training and testing sets.
- Cross-Validation: Dividing data into multiple folds to ensure the model generalizes well across unseen data.
In a spam email classifier, high accuracy but low recall could mean many spam emails are still landing in users’ inboxes — a sign of poor real-world performance.
6- Hyperparameter Tuning:
Every ML model comes with hyperparameters — settings that influence how the model learns. Unlike model parameters (which are learned), hyperparameters must be set manually or tuned automatically.
- Learning Rate: Controls how big a step the model takes during optimization.
- Number of Trees: In Random Forests.
- Number of Layers and Neurons: In deep learning models.
- Grid Search: Trying every combination from a pre-defined set.
- Random Search: Trying random combinations.
- Bayesian Optimization: Using probabilistic models to find optimal settings faster.
7- Deployment:
Once trained, tuned, and tested, the model is ready for deployment into real-world environments.
- Cloud-Based Deployment: Using services like AWS SageMaker, Azure ML, or Google AI Platform.
- Edge Deployment: Running lightweight models on mobile devices, IoT devices, or embedded systems.
- API Integration: Exposing models through APIs for use in web or mobile applications.
- Monitoring: Tracking model performance in production is crucial to detect model drift (when real-world data starts differing from training data).
- Scaling: Ensuring the model can handle real-world traffic and requests.
Netflix uses deployed machine learning models to instantly recommend shows based on viewer interactions, adjusting recommendations in real-time based on user behavior.
The NIH highlights that AI and Machine Learning are projected to save the healthcare industry approximately $150 billion annually by 2026. The journey of building a machine learning model — from data collection to deployment — is a meticulous process involving art, science, and a lot of iteration.
Understanding how machine learning works enables organizations to unlock the full potential of their data and empower machines to make meaningful, impactful decisions.
In the next part, we’ll dive deeper into the Machine Learning development services Lifecycle, exploring how ML projects evolve from idea to long-term production systems.
90% of Businesses Pick the Wrong Dev Team — Don’t Be One of Them
Let's Talk
One wrong hire can stall your entire roadmap—this vetted match helps you start right, scale fast, and avoid costly mistakes.
Machine Learning Development Lifecycle:
Building a successful machine learning model isn’t a one-time task. It follows a structured, methodical process known as the Machine Learning Development Lifecycle. Each phase ensures the project moves logically from conception to deployment and ongoing improvement.
Let’s break down this lifecycle into its essential stages.
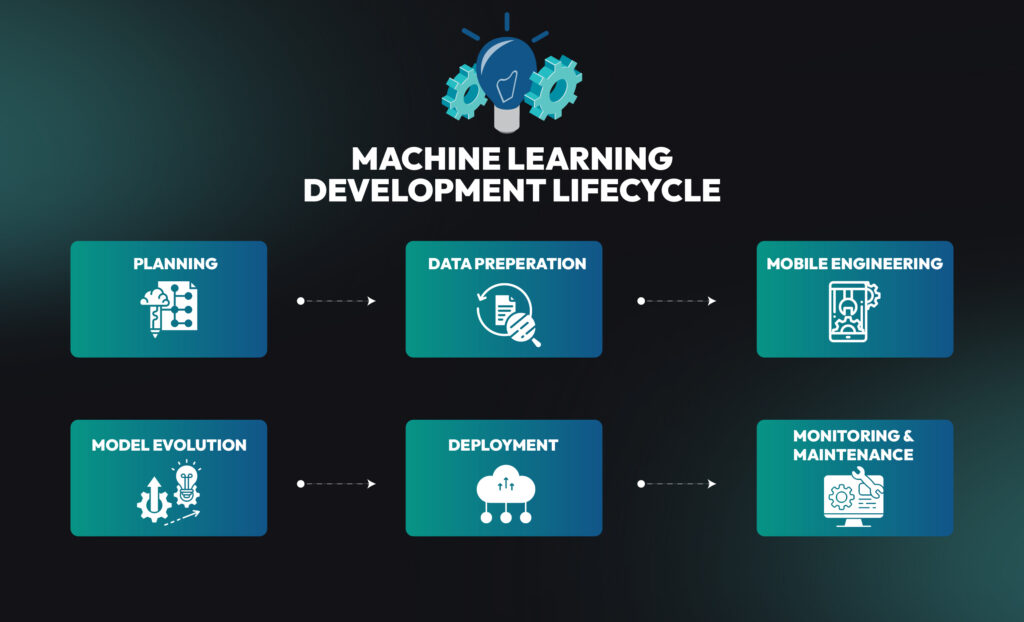
1- Planning:
Every successful ML project starts with careful planning. Rushing into data collection or model building without a clear goal almost guarantees wasted time and resources.
- Problem Definition: What exactly are we trying to predict, classify, or automate?
- Success Metrics: Defining how model success will be measured (accuracy, precision, recall, etc.).
- Stakeholder Engagement: Gathering business requirements from those who will use or be impacted by the model.
- Feasibility Study: Ensuring enough quality data exists to support the project.
Without a clear plan, projects are vulnerable to scope creep, misaligned expectations, and ultimate failure — no matter how good the technical execution is.
2- Data Preparation:
After planning, the next step is data preparation, also known as data wrangling. This critical step transforms raw, messy data into a form suitable for modeling.
- Data Cleaning: Handling missing values, correcting errors, and removing duplicates.
- Feature Engineering: Creating new variables that make hidden patterns more accessible to algorithms.
- Data Splitting: Dividing the dataset into training, validation, and testing sets.
In fraud detection, feature engineering might involve creating a new variable that measures “time since last transaction” — highly predictive of fraudulent behavior.
3- Model Engineering:
With clean data in hand, it’s time for model engineering — selecting and designing the right machine learning algorithms.
- Algorithm Selection: Based on problem type (classification, regression, clustering).
- Baseline Model Creation: Building simple models first to set a benchmark.
- Model Complexity Adjustment: Choosing the right balance between underfitting and overfitting.
This phase is where Machine Learning Engineers apply their knowledge of different models, from simple linear regression machine learning models to advanced neural networks.
Model engineering is both an art and a science, requiring intuition, experimentation, and deep technical expertise.
4- Model Evolution:
Even after deploying an ML model, the work isn’t over. Model evolution refers to the continuous improvement cycle needed to maintain high performance.
- Retraining Models: As new data becomes available.
- Monitoring Concept Drift: Identifying when underlying data patterns change.
- Ensemble Methods: Combining multiple models to improve accuracy.
An e-commerce recommendation engine must retrain frequently to incorporate seasonal changes in customer preferences.
5- Deployment:
Deploying a machine learning model means moving it from the research environment into a production system where it can generate real-world predictions.
- Batch Deployment: Running the model at regular intervals (e.g., nightly).
- Real-Time Deployment: Serving predictions instantly via APIs.
- Latency Requirements: Real-time systems must return predictions quickly.
- Resource Management: Ensuring enough computational power without overloading infrastructure.
6- Monitoring and Maintenance:
Post-deployment, ongoing monitoring and maintenance are vital. Models can degrade over time if not carefully watched — a phenomenon known as model drift.
- Prediction accuracy over time.
- Input data changes (feature drift).
- Business KPI alignment.
- Scheduled Retraining: Updating the model with fresh data.
- Performance Audits: Periodically reviewing model outputs for fairness and bias.
- Alerting Systems: Notifying teams if performance drops below a set threshold.
Common Machine Learning Algorithms:
Choosing the right algorithm is pivotal in answering what is machine learning effectively. Different algorithms solve different types of problems. Let’s walk through some of the most widely used types of machine learning models.

1- Linear Regression:
- Predicting house prices.
- Forecasting sales based on advertising spend.
- Easy to interpret.
- Works well for linearly separable data.
2- Logistic Regression:
- Predicts probabilities.
- Assigns outcomes based on thresholds (e.g., email being spam or not).
- Customer churn prediction.
- Disease diagnosis based on symptoms.
3- Clustering:
- K-Means Clustering: Assigns points to clusters based on proximity to centroids.
- Hierarchical Clustering: Builds nested groups based on similarity.
- Customer segmentation.
- Market research analysis.
- Image compression.
4- Decision Trees:
- The tree branches based on feature values.
- Each branch represents a decision rule.
- Easy to understand and visualize.
- Handles both numerical and categorical data.
5- Random Forests:
- Reduces overfitting compared to single trees.
- Can handle missing values and large datasets well.
- Fraud detection.
- Customer recommendation engines.
6- Neural Networks:
Neural Networks are the backbone of modern deep learning and have revolutionized tasks once thought to be impossible for machines.
- Made of layers of nodes (neurons) interconnected with weights.
- Learn complex patterns through backpropagation.
- Image recognition (e.g., tagging friends in Facebook photos).
- Natural Language Processing (e.g., real-time translations).
Importance of Machine Learning:
In the modern world, understanding what is machine learning isn’t just a matter of curiosity — it’s becoming essential. Machine Learning has revolutionized industries, changed business models, and reshaped the way humans interact with technology.
NVIDIA reveals that 91% of financial services companies are actively deploying AI and ML models in production. Let’s explore its impact across key industries.
Healthcare:
One of the most transformative applications of machine learning lies in healthcare. From early disease detection to personalized treatment plans, ML is enhancing patient care and operational efficiency.
Key Applications:
- Predictive Analytics: Forecasting disease outbreaks and patient admissions.
- Medical Imaging: Detecting tumors, fractures, and anomalies using image recognition.
- Drug Discovery: Accelerating the identification of new potential treatments.
- Personalized Medicine: Tailoring treatments based on genetic profiles.
Example:
Why It Matters:
- Faster diagnoses save lives.
- Automation reduces human error.
- Personalized care leads to better patient outcomes.
Finance:
Key Applications:
- Fraud Detection: Identifying unusual transactions in real-time using anomaly detection.
- Algorithmic Trading: ML models analyze market data and news faster than human traders.
- Risk Assessment: Scoring loan applications based on alternative data sources.
- Customer Insights: Personalizing banking experiences using behavioral data.
Example:
Why It Matters:
- Improved security and trust.
- Better investment strategies.
- Enhanced customer experiences.
Transportation:
Key Applications:
- Autonomous Driving: Vehicles like Tesla use deep learning to navigate complex environments.
- Traffic Prediction: ML models predict congestion and optimize routes.
- Fleet Management: Companies use ML to manage vehicle maintenance schedules and optimize deliveries.
Example:
Why It Matters:
- Reduced traffic accidents.
- Lower emissions through optimized routes.
- More efficient delivery systems.
Real-World Applications of Machine Learning:
1- Voice Assistants:
- Speech Recognition: Converting spoken words into text.
- Intent Recognition: Understanding the user’s goal.
- Action Execution: Performing the desired task.
2- Social Media Personalization:
- Recommendation Systems: Suggesting friends, groups, pages, or content.
- Computer Vision: Tagging people in photos automatically.
- Sentiment Analysis: Gauging user emotions based on posts or comments.
3- E-commerce Optimization:
In e-commerce, machine learning plays a huge role in:
- Product Recommendations: Suggesting items based on browsing history.
- Dynamic Pricing: Adjusting product prices in real-time based on demand.
- Inventory Management: Predicting stock needs based on shopping trends.
4- Fraud Detection:
Across sectors, fraud is a critical challenge — and ML offers powerful tools to combat it.
- Real-time anomaly detection catches suspicious transactions as they occur.
- Supervised learning models classify transactions based on historical fraud data.
- Unsupervised models discover new fraud patterns without prior labeling.
5- Entertainment and Content Streaming:
Platforms like Netflix, YouTube, and Spotify use machine learning and deep learning models to recommend personalized content based on your past interactions.
- Collaborative Filtering: Suggesting content based on similar users’ preferences.
- Content-Based Filtering: Suggesting content similar to what you’ve already enjoyed.
Without machine learning, personalized entertainment as we know it today would simply not exist.
Read More Related Blogs:
Conclusion:
Throughout this blog, we’ve journeyed into the fascinating world of machine learning, answering the foundational question: what is machine learning?
Here’s a quick recap of what we covered:
- Introduction to Machine Learning: Understanding how machines learn from data without being explicitly programmed.
- Artificial Intelligence vs Machine Learning vs Deep Learning: Clarifying the relationships and differences among these interconnected fields.
- Types of Machine Learning: Exploring supervised, unsupervised, semi-supervised, and reinforcement learning approaches.
- How Machine Learning Works: From data collection to deployment, detailing each stage of a successful ML project.
- Machine Learning Development Lifecycle: Understanding how models are built, maintained, and evolved over time.
- Common Machine Learning Algorithms: An overview of key models powering today’s innovations.
- Real-World Applications and Importance: Seeing how ML transforms industries like healthcare, finance, transportation, e-commerce, and entertainment.
The Future of Machine Learning:
As we look ahead, the future of machine learning holds even more transformative possibilities.
Emerging trends such as explainable AI, edge computing, and hyperautomation are pushing ML beyond traditional applications. Ethical concerns surrounding bias, transparency, and accountability are also driving the development of more responsible and fair models.
We are witnessing a democratization of machine learning tools — making them accessible even to non-technical users through no-code/low-code platforms.
In the coming years, machine learning and deep learning will become an even more integrated part of daily life, embedded into everything from healthcare diagnostics to climate modeling.
The global AI market is projected to reach $1,339 billion by 2030, up from an estimated $214 billion in 2024.
The exciting part? We are just scratching the surface.
Your Next Step:
If you’re inspired by what machine learning can do, the best time to start exploring it is now.
- Dive into beginner-friendly programming languages like Python.
- Experiment with open-source datasets and simple models.
- Build small projects — whether it’s predicting house prices or classifying images.
Remember: The path to mastering ML starts with understanding the basics and consistently practicing hands-on.
Machine learning isn’t just a career opportunity — it’s a chance to be part of shaping the future.
Keep learning, stay curious, and embrace the endless possibilities that machine learning offers!
Ready to Work with New York’s Best Software Development Experts?
Let's Talk
Let’s turn your ideas into intelligent, high-performing solutions—built for scale, speed, and ROI.
Frequently Asked Questions (FAQs)
1. What is Machine Learning and How Is It Used in Real Life?
Machine learning (ML) is a subset of artificial intelligence that enables systems to learn from data without being explicitly programmed. From personalized Netflix recommendations to fraud detection in banking, machine learning applications are reshaping industries.
2. How Does a Machine Learning Engineer Contribute to AI Development?
A machine learning engineer builds and optimizes ML models, bridges the gap between data science and software engineering, and ensures models scale in real-world environments. At Kodexo Labs, our ML engineers play a critical role in deploying intelligent systems for clients across various sectors.
3. What Is the Difference Between Supervised and Unsupervised Machine Learning?
Supervised machine learning uses labeled data to train models, while unsupervised learning finds patterns in unlabeled data. Understanding supervised vs unsupervised machine learning is fundamental when selecting the right ML approach for your problem.
4. What Are the Types of Machine Learning and Their Applications?
The primary machine learning types are: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Each has its own unique applications, from image classification to autonomous vehicles.
5. How Do Neural Networks Work in Machine Learning?
Neural networks are inspired by the human brain and form the foundation of many deep learning systems. They are especially powerful in image recognition, language modeling, and sequence prediction tasks.
6. What Are the Core Differences Between AI, Machine Learning, and Deep Learning?
Artificial intelligence (AI) is the broadest concept, encompassing both machine learning (ML) and deep learning (DL). ML focuses on algorithms that learn from data, while DL is a subset of ML using deep neural networks for complex problem solving.
7. What Is Machine Learning Operations (MLOps) and Why Does It Matter?
Machine Learning Operations (MLOps) refers to practices that unify ML system development and operations. It includes continuous training, model monitoring, and lifecycle management—something we emphasize in every ML deployment at Kodexo Labs.
8. How Does Classification Work in Machine Learning?
Classification in machine learning involves categorizing input data into predefined labels. It’s widely used in spam detection, medical diagnosis, and sentiment analysis.
9. What Programming Languages Are Best for Machine Learning?
Popular machine learning languages include Python, R, and Julia. Python, with its libraries like Scikit-learn and TensorFlow, remains the top choice for both researchers and developers at Kodexo Labs.
10. Is Linear Regression Still Relevant in Modern Machine Learning?
Absolutely. Linear regression remains one of the most fundamental and interpretable algorithms in the ML toolkit, often used as a baseline model for predictive tasks.