
Contents
AI has become an integral part of our lives, transforming the way we interact with technology and the world around us. As technology continues to evolve, the race to develop more advanced and capable AI systems intensifies.
Google’s latest innovation, Gemini AI, is a significant leap forward in AI research and development. You might have already heard about it. It’s been viral and continuously discussed throughout social media, even before its release. But guess what? Google DeepMind has launched Gemini AI now, on 9th December 2023.
This groundbreaking technology has generated significant buzz in the tech community, promising to redefine the boundaries of AI capabilities. In this blog post, we’ll explore the key aspects of Gemini AI, from its launch and features to its potential impact on the industry.
Google Gemini Release Date:
DeepMind officially unveiled Gemini to the world on 9th December 2023, marking a milestone in the field of artificial intelligence. The launch event showcased the culmination of years of research and development, highlighting the dedication and expertise of DeepMind’s team.
Boost your to the next level with AI-Based Integration

What is Google Gemini AI?
Gemini AI is Google DeepMind new multimodal AI model, a product of years of research and development at Google DeepMind. It is the first model to beat human experts on MMLU (Massive Multitask Language Understanding), a widely used technique to gauge an AI model’s level of understanding and problem-solving skills.
It is designed to understand and combine different types of information, such as text, code, audio, image, and video, making it a versatile and powerful tool for various applications.
Gemini is optimized for different sizes and use cases, allowing it to be tailored to specific tasks and requirements. This adaptability makes it a valuable resource for a wide range of applications, from consumer-facing AI apps to enterprise solutions.
Applications of Google DeepMind Gemini AI:
Gemini is being integrated into numerous Google products and services, showcasing its versatility and potential. Some of the products and services that will feature Gemini include:
- Google Search
- Google Ads
- Google Chrome
- Bard Chatbot
- Search Generative
These integrations will allow Gemini to demonstrate its capabilities across various domains, from providing relevant search results to enhancing user experiences in advertising and web browsing.
Gemini AI Performance:
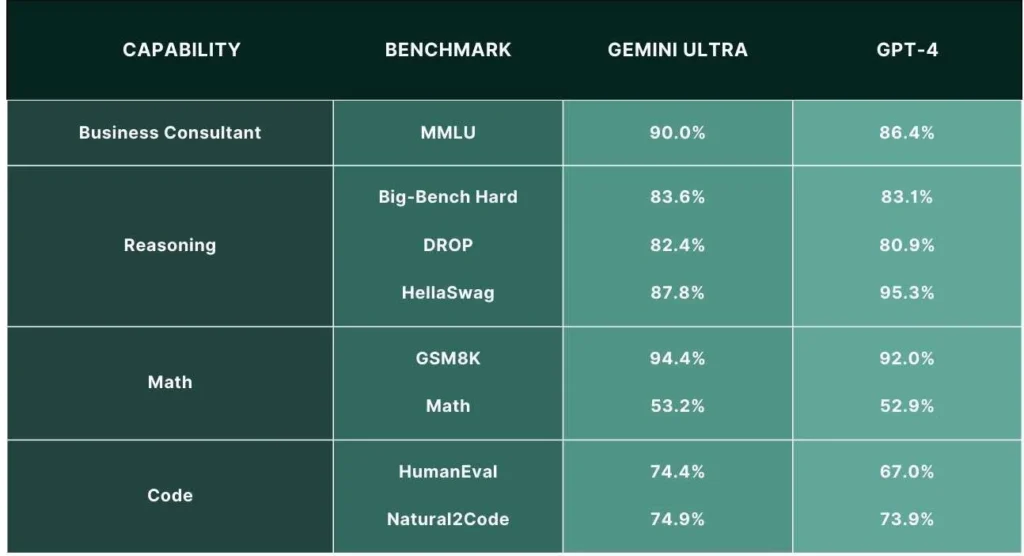
Gemini AI has been rigorously tested and fine-tuned for safety, ensuring that it meets high standards of performance and reliability. In comparison to other AI models, such as OpenAI, Gemini outperforms in general tasks, reasoning capabilities, math, and code. Its ability to excel in coding benchmarks like HumanEval and Natural2Code demonstrates its expertise in handling complex programming tasks.
Key Features of Google DeepMind Gemini AI:
Google Gemini is a highly capable multimodal AI model that can understand and combine different types of information, such as text, code, audio, image, and video. It is optimized for different sizes and use cases, making it a versatile and powerful tool for various applications. Here are some of the key features and capabilities of Google Gemini:
Multimodality:
Gemini is built for multimodality, which means it can reason seamlessly across text, images, video, audio, and code. This makes it a valuable resource for a wide range of applications, from consumer-facing AI apps to enterprise solutions.
Massive Multitask Language Understanding (MMLU):
Gemini is the first model that has outperformed human experts on MMLU, which involves understanding and interpreting language and content. This demonstrates its expertise in handling complex language tasks.
General Tasks:
Gemini outperforms OpenAI in general tasks, such as reasoning capabilities, math, and code. Its ability to excel in coding benchmarks like HumanEval and Natural2Code demonstrates its expertise in handling complex programming tasks.
Training and Architecture:
Gemini 1.0 was trained on Tensor Processing Units (TPUs) jointly across image, audio, video, and text data to build a model with strong generalist capabilities across modalities. It takes textual input and a wide variety of audio and visual inputs, such as natural images.
Safety and Governance:
The Gemini models used a structured approach to deploy the models responsibly to identify, measure, and manage the foreseeable downstream societal impacts of the models. Ethics and safety reviews are conducted with Google DeepMind’s Responsibility and Safety Council (RSC). During the Google Gemini project, the RSC sets specific evaluation targets.
Availability:
Google Gemini is available in different sizes and capabilities, catering to a wide range of use cases and requirements. Gemini Ultra is not yet available, as Google is running more safety and trust checks to ensure the solution suits the current market.
However, it is making Gemini Ultra available to certain developers and partners in “beta mode.” Google plans to license Gemini to customers through Google Cloud, allowing them to incorporate this advanced AI technology into their own applications.
Google DeepMind Gemini AI Model Sizes:
The Google Gemini AI model is being released in three sizes, each tailored to specific use cases and requirements. The three sizes of Gemini are:
Gemini Nano:
- Designed to run on smartphones, specifically the Google Pixel 8.
Built to perform on-device tasks that require efficient AI processing without connecting to the cloud, such as suggesting replies within chat applications or summarizing text.
Gemini Pro:
- Designed to run on Google’s data centers.
It is intended to power the latest version of the company’s AI chatbot, Bard, and is equipped to handle advanced reasoning, planning, understanding, and other capabilities.
Gemini Ultra:
- The most powerful and largest version of the Gemini AI model.
Google has postponed the launch of Gemini Ultra as it undergoes more safety and trust checks to ensure it is suitable for the market. However, it is being made available to certain developers and partners in “beta mode”.
Google DeepMind Gemini AI Capabilities:
- Google Gemini is a highly capable AI model that can understand and generate any input and output based on different languages, images, videos, and more.
- Gemini is built for multimodality, which means it can reason seamlessly across text, images, video, audio, and code
- It is the first model that has outperformed human experts on Massive Multitask Language Understanding (MMLU), which involves understanding and interpreting language and content.
- Gemini can generate code based on different inputs, generate text and images combined, and reason visually across languages.
- It can also understand and generate video, images, and audio, making it a versatile tool for various applications.
Google DeepMind Gemini AI Output Generation:
Based on the video by Google itself, here are some examples of output generation for the given inputs:

Multimodal Dialogue:
Gemini can engage in multimodal dialogue, combining text and image recognition to understand and respond to user inputs.
For example, the user can draw on a piece of paper and ask Gemini to guess what it sees, and Gemini can analyze the image and provide a reasonable analysis.
Multilingualism:
Gemini can translate between languages based on user inputs. In the video, the user asks the AI to tell them how to pronounce a word in a different language, and Gemini provides both text and audio responses.
Game Creation:
Gemini can be used to prototype multimodal games, such as a geography guessing game where users have to point at a map to make their guess. The AI can generate clues based on the user’s input and provide a timer to keep track of the game.
Visual Puzzles:
Gemini can reason about visual puzzles, such as connect-the-dots pictures. The AI can quickly recognize images and respond within and track games in real time.
Image and Text Generation:
Gemini can generate text and images combined, as well as generate ideas for creating objects, such as an octopus with blue and pink tentacles.
Logic and Puzzles:
Gemini can be used to invent new translations between different inputs and outputs, showcasing its logic and puzzle-solving capabilities.
Making Connections:
The AI can make connections between different visual inputs, such as categorizing two random objects placed on a table and grouping them together based on visual context.
Logic and Spatial Reasoning:
The AI is comfortable with answering logic-based visual puzzles and identifying various aspects of them before offering a solution. It can also reason about new translations between different inputs and outputs, showcasing its logic and puzzle-solving capabilities.
Translating Visuals:
Gemini can translate visuals, such as identifying and playing AI-generated music based on the user’s drawing of a guitar and adjusting the music as the user adds more instruments and themes.
Potential of Google Gemini:
Gemini’s capabilities extend beyond mere data processing:
- In demonstrations, it accurately identified objects from both hand-drawn images and physical objects, such as a blue duck.
- The AI model also exhibited advanced reasoning skills, as seen in a demo where it correctly assessed a roller coaster with a loop as more fun than one without.
- Additionally, Gemini’s prowess in educational assistance was highlighted through its ability to read, evaluate, and explain students’ math answers.
- Google also emphasized Gemini’s coding capabilities, with proficiency in languages like Python, Java, C++, and Go.
Integrating Google Gemini AI to Various Applications
- The integration of Gemini extends to various applications, including powering Summarize in the Recorder app and Smart Reply in Gboard.
- Furthermore, Gemini is being tested in Google Search to enhance generative AI capabilities and reduce latency.
- Plans are underway to integrate Gemini into Search, Chrome, Ads, and Duet AI – the AI-powered collaborator available across Google Cloud and IDEs.
Conclusion:
Gemini is expected to be the most powerful AI ever built, with sophisticated multimodal capabilities. It can master human-style conversations, language, and content, understand and interpret images, code prolifically and effectively, drive data and analytics, and be used by developers to create new AI apps and APIs.
In conclusion, Google Gemini’s integration into various applications and its advanced multimodal capabilities make it a significant leap forward in the field of generative AI development, with the potential to drive consumer engagement and maintain Google’s dominance in the technology sector.