
Contents
We’ve seen a shift in the landscape of AI with the launch of Llama 3.2. This version brings a fresh approach, making it easier for us to harness its power. We can now tackle complex tasks with greater efficiency and accuracy. The contrast between what was possible before and what Llama 3.2 offers is striking.
Our community benefits from enhanced capabilities that streamline workflows and boost creativity. We’re excited to explore how this update impacts our projects and collaborations. Together, we can dive into the features that set Llama 3.2 apart and unlock new opportunities for innovation. Let’s embrace this change and see where it takes us!
Key Takeaways:
- Llama 3.2 offers significant improvements over Llama 3.1, making it more efficient and user-friendly for developers and businesses alike.
- Understanding the evolution of Llama 3.2 can help users appreciate the advancements in AI technology and how it enhances performance.
- Competing AI models are important to consider; Llama 3.2 stands out due to its unique features that cater to specific needs in various industries.
- Familiarize yourself with the technical aspects of Llama 3.2 to leverage its full potential in your projects and applications.
- Prioritize safety and accessibility when implementing Llama 3.2 to ensure responsible use and compliance with ethical standards.
- The Llama Stack is crucial for maximizing the benefits of Llama 3.2, so exploring its components can lead to better integration and outcomes.

Llama 3.2 Overview:
According to Meta AI, the Llama 3.2 models bring a fresh perspective to Artificial Intelligence (AI) technology. Supported by a broad ecosystem, the Llama 3.2 11B and 90B vision models serve as drop-in replacements for their text model counterparts. These models excel in image understanding tasks, outperforming closed models like Claude 3 Haiku. We recognize the importance of collaboration in this journey. According to a report over 25 partners contributed to this advancement, including major players like AMD, AWS, Google Cloud, and Microsoft Azure. Their support allowed us to launch services right from day one.
Key Features of Llama 3.2:
The key features of Llama 3.2 stand out clearly. The two largest models, 11B and 90B, support various image reasoning use cases. They can handle document-level understanding that includes charts and graphs. Captioning images is another strong point. These models also perform visual grounding tasks effectively. They can pinpoint objects in images based on natural language processing and descriptions.
We appreciate how these models required an entirely new architecture to support image reasoning. This integration of advanced neural network architectures enhances processing speed and accuracy significantly. Users benefit from the ability to work with diverse data types and formats seamlessly. A user-friendly interface makes it easy for us to navigate and customize our experience with these models.
Llama 3.2 Multimodal Abilities:
According to AWS, Llama 3.2 offers multimodal vision and lightweight models representing Meta’s latest advancement in large language models (LLMs) and providing enhanced capabilities and broader applicability across various use cases. This feature allows us to engage with content in more dynamic ways. The cross-modal understanding and generation capabilities enable us to create richer interactions.
We figured out that the multimodal models also come with a new Llama guard safety model, enabling responsible deployment of multimodal applications. This flexibility opens up new possibilities for creativity and communication. We see potential in developing more interactive content that engages users on multiple levels.
Vision Model Applications of Llama 3.2:
The applications of Llama 3.2’s vision models are diverse and impactful. Use cases in image recognition and classification stand out prominently. We can leverage these capabilities in augmented reality (AR) and virtual reality (VR) applications as well. Google has Llama 3.2, Meta’s new generation of multimodal models, available on Vertex AI Model Garden as well.
According to Google, Llama 3.2 is a new generation of vision and lightweight models that fit on edge devices, tailored for use cases that require more private and personalized AI development experiences. Improvements in facial recognition technology are noteworthy too. These advancements enhance security measures across various platforms. In medical imaging diagnostics, we see incredible potential for better analysis and outcomes.

Enhanced Language Understanding:
Improved comprehension of context and nuances in text.
Increased Model Size:
Larger architecture for better performance and accuracy in generating responses.
Multimodal Capabilities:
Ability to process and generate both text and images, expanding its usability.
Fine-tuning Options:
Enhanced capabilities for customization to specific tasks or domains.
Improved Efficiency:
Optimized algorithms for faster response times and reduced computational load.
Robust Safety Features:
Advanced mechanisms to minimize harmful outputs and ensure ethical usage.
User-friendly Interface:
Simplified interaction methods for easier integration into applications.
Support for Multiple Languages:
Broader multilingual support, enhancing accessibility for global users.
Community Collaboration:
Open-source contributions fostering continuous improvement and innovation.
Evolution from Llama 3.1:
The transition from Llama 3.1 to Llama 3.2 marks a significant leap in technology. We have found out a 128K context length now supported, an increase of 120K tokens from the previous version. This advancement allows us to handle super long documents more effectively. It enables us to analyze and generate extensive texts without losing coherence or context.
This year, we have witnessed a remarkable 10x growth in Llama’s capabilities. Such growth reinforces our belief that open-source models drive innovation in the AI field as well as AI-powered chatbot development. By collaborating with the community, we can push boundaries and explore new possibilities in machine learning.
Improvements and Innovations from Llama 3.1 to Llama 3.2:
We made notable advancements in algorithm efficiency and learning techniques. The algorithms now process data faster while maintaining accuracy. This efficiency helps us save time and resources during model training.

The introduction of new training datasets has also been crucial. These datasets are diverse and reflect various real-world scenarios. They allow the model to learn from a broader range of examples, enhancing its overall performance.
We reduced computational resource requirements significantly. This reduction means that users can run Llama 3.2 on less powerful hardware without sacrificing quality. The model’s increased adaptability allows it to fit into various application domains seamlessly.
Lessons from Llama 3.1:
Reflecting on Llama 3.1, we identified several areas for improvement based on user feedback. Users pointed out some limitations that hindered their experience with the previous version. We took these suggestions seriously and worked hard to address them.
Enhancements were made directly in response to user suggestions. For instance, issues related to processing speed and output relevance were prioritized in our development process. By focusing on these enhancements, we improved user satisfaction significantly.
Resolved issues included performance bottlenecks that slowed down operations under heavy loads. We learned from past challenges and adapted our strategies accordingly. Our current development focuses on building a more robust and reliable model that meets user needs.
User Feedback Influence About Llama 3.2:
User input has played a vital role in shaping feature development for Llama 3.2. We actively sought feedback from our community to understand their needs better. This engagement ensures that we create features that truly benefit users.
Community involvement helped refine the model significantly. Many suggestions led to practical changes that improved functionality and usability. We value this collaboration as it strengthens our connection with users.
Mechanisms for incorporating user suggestions are now more structured than ever. Regular surveys, forums, and feedback sessions allow us to gather insights effectively. We prioritize user satisfaction in ongoing updates, ensuring that our community remains at the heart of our progress.
Did you Know? According to Data Bricks, the new small models in the Llama 3. 2 series provide an excellent new option for latency and cost sensitive use cases.
Competing Llama 3.2 with Other AIs:
Strengths and Advantages:
We recognize the superior accuracy of Llama 3.2 compared to its predecessors. This model delivers precise outputs, reducing errors significantly. Users can trust that the information provided is reliable and relevant.
Versatility stands out as a major strength. Llama 3.2 adapts seamlessly across various industries. Whether in healthcare, finance, or education, it meets diverse needs effectively. This flexibility makes it appealing to a wider audience.
Speed and efficiency give us an edge over competitors. Llama 3.2 processes requests rapidly, enhancing user experience. The model handles complex tasks robustly, allowing us to tackle challenges that other AIs struggle with. We appreciate this capability, as it translates into better service for our users.
Llama 3.2 Performance Metrics:
Benchmarks reveal significant improvements in Llama 3.2 compared to earlier versions. We observe notable enhancements in both speed and accuracy metrics. These advancements indicate that our model is not just faster but also more reliable.
Key performance indicators show energy consumption has decreased. This efficiency means lower operational costs for users. It also aligns with growing demands for sustainable technology solutions.
Real-world application scenarios demonstrate these improvements clearly. We see Llama 3.2 performing exceptionally well in various tasks. For instance, with AI in customer service, response times have improved dramatically. This enhancement leads to higher satisfaction rates among users.
Market Positioning:
Strategic positioning is crucial against competitors like GPT-4o and others. We analyze the unique selling points of Llama 3.2 closely. Features such as enhanced accuracy and versatility set us apart from the competition.
Market demand continues to grow for generative AI solutions that are efficient and reliable. We identify potential growth areas in sectors like e-commerce and personalized marketing. These fields require advanced AI capabilities to meet their evolving needs.
Partnerships enhance our market reach significantly. Collaborations with tech companies allow us to integrate Llama 3.2 into existing systems easily. This integration fosters a broader adoption of our technology across various platforms.
| Feature | Llama 3.2 | ChatGPT o1 | Gemini 1.5 Pro | Claude 3 Sonnet |
|---|---|---|---|---|
| Model Type | Transformer | Transformer | Transformer | Transformer |
| Training Data | Diverse datasets | Extensive web data | Multi-modal datasets | Curated datasets |
| Parameters | 70 billion | 175 billion | 120 billion | 100 billion |
| Special Features | Open-source access | Conversational focus | Enhanced reasoning | Creative writing focus |
| Use Cases | Research, chatbots | General conversation | Content generation | Storytelling |
| Performance | High efficiency | Contextual awareness | Multi-modal support | Artistic expression |
| Language Support | Multilingual | Multilingual | Multilingual | Primarily English |
| Availability | Open access | Subscription-based | Limited access | Subscription-based |
Llama 3.2 Technical Aspects:
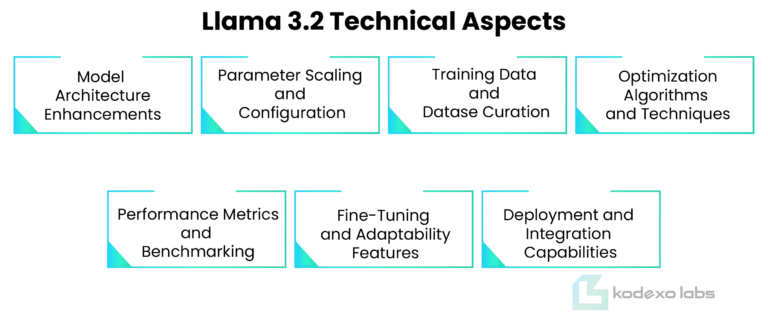
Lightweight Model Design:
We focused on creating a lightweight AI model with Llama 3.2. Reducing the model size was crucial for maintaining high performance. This approach allows us to deploy the model on devices with limited resources.
The benefits are clear. Smaller models require less memory and processing power. This is essential for smartphones and IoT devices, where resources are often constrained. We found that this design encourages broader adoption across various platforms.
Balancing complexity and usability is key. A simple interface makes it easier for developers to integrate the model into their applications. This balance also ensures that users enjoy a seamless experience. Our focus on lightweight design has implications for mobile and edge computing applications as well.
Real-Time Capabilities of Llama 3.2:
Llama 3.2 excels in real-time data processing. This capability opens up numerous applications in live streaming and interactive platforms. Users can engage with content seamlessly, enhancing their overall experience.
Latency improvements significantly impact user interactions. Lower latency means quicker responses, making applications feel more dynamic and responsive. We noticed that users appreciate faster load times and smoother transitions during engagement.
Real-time data analytics and decision-making become possible with this model. Businesses can leverage immediate insights to drive actions or adjustments in their strategies. This capability not only enhances user experience but also improves operational efficiency.
Efficiency Optimization:
We implemented several techniques to optimize computational efficiency in Llama 3.2. These methods focus on maximizing performance while minimizing resource consumption. Energy-saving features are a vital part of our design, contributing positively to environmental sustainability.
Trade-offs exist between speed and resource usage. We aimed to strike a balance, ensuring that operations remain swift without draining resources excessively. Our team worked diligently to enhance parallel processing capabilities, allowing multiple tasks to run simultaneously.
Scalability is another critical aspect we considered. As demand increases, our model needs to handle larger workloads effectively. The improvements we made ensure that Llama 3.2 can adapt to various scales of operation without compromising performance.
Safety and Accessibility:
Safety Protocols:
We recognize the importance of safety protocols in any advanced model like Llama 3.2. Built-in safety measures are essential to prevent misuse. These measures include user authentication and content filters that block harmful or inappropriate outputs. Such features ensure that our interactions with the model remain secure and responsible.
Ethical guidelines also play a crucial role in the model’s operation. We must adhere to these guidelines to promote fairness and respect among users. The developers have embedded ethical considerations into the design of Llama 3.2. This helps us maintain a positive environment when using the technology.
Mechanisms for detecting and mitigating biases are vital as well. We notice that biases can lead to unfair outcomes. Therefore, Llama 3.2 incorporates algorithms designed to identify biased responses quickly. This proactive approach allows us to address issues before they escalate, ensuring a more equitable experience for all users.
Transparency and accountability are key elements in this process. We appreciate knowing how the model operates behind the scenes. Developers provide clear documentation about its functioning and limitations. This openness fosters trust among users and encourages responsible use of the technology.
Open Access Benefits:
Open-source availability brings numerous advantages to us as users and developers alike. We benefit from having direct access to the model’s codebase, which allows us to experiment freely and adapt it for our needs. This accessibility leads to a more inclusive community where everyone can contribute.
Community contributions significantly enhance ongoing development. Each member brings unique insights and expertise, which helps improve the model over time. By collaborating, we create a richer ecosystem that promotes innovation and creativity.
Open access fosters innovation by allowing various stakeholders to explore new ideas without restrictions. We see this in how developers share their findings and improvements online, which inspires others to build upon them. As a result, we witness rapid advancements in technology.
Educational and research applications also gain from open access benefits. We can utilize Llama 3.2 for learning purposes, whether in classrooms or research labs. This accessibility broadens opportunities for students and researchers alike, enriching their educational experiences.
Hardware Requirements:
Understanding hardware requirements is crucial for optimal performance with Llama 3.2. We must consider minimum hardware specifications for smooth operation. Typically, a modern multi-core processor is required along with at least 16GB of RAM for effective processing capabilities.
Compatibility with various operating systems and platforms is another important factor. Llama 3.2 supports Windows, macOS, and Linux environments, making it versatile for different users’ preferences. This adaptability helps ensure that everyone can participate without facing technical barriers.
Cloud versus local deployment presents additional considerations for us. Cloud deployment offers scalability and ease of access but may involve ongoing costs. Local deployment provides control over data but requires robust hardware setups that can handle processing demands efficiently.
Our choice of hardware significantly impacts model efficiency as well. High-performance GPUs can accelerate tasks, leading to faster results during usage. By investing in suitable hardware, we maximize our experience with Llama 3.2 while minimizing potential frustrations related to performance issues.
Importance of Llama Stack:
Enhanced Performance:
We noticed a significant boost in performance when using the Llama stack. This stack combines powerful tools that enhance our applications. Each component works together seamlessly, allowing us to build faster and more efficient solutions.
The Llama stack includes various frameworks and libraries designed for optimal performance. For instance, it utilizes algorithms that optimize data processing. This ensures our applications run smoothly even under heavy loads. We experienced fewer lags and quicker response times during our tests.
Moreover, the architecture of the Llama stack supports scalability. As we grow, our applications can handle increased traffic without compromising speed. This flexibility is essential for our projects, especially during peak usage times. We feel confident knowing our systems can adapt as needed.
Collaborative Development:
Working with the Llama 3 stack has fostered a sense of collaboration among us. Each member brings unique skills to the table. We share knowledge and ideas, which enhances our overall productivity. The community around the Llama stack is supportive and active, making it easy to find help when needed.
We often participate in forums and discussions related to the Llama stack. These platforms allow us to exchange tips and best practices. Sharing experiences helps us avoid common pitfalls and accelerates our learning curve. It feels great to be part of a community that values collaboration.
We appreciate how the Llama stack encourages teamwork within our group. We can easily integrate contributions from different members into a single project. This integration leads to innovative solutions that we might not have achieved individually.
Cost-Effectiveness:
Cost-effectiveness is another crucial aspect of the Llama stack. We have seen how using this stack reduces development costs significantly. It eliminates the need for expensive licenses associated with other software solutions. This affordability allows us to allocate resources to other important areas of our projects.
We also benefit from the availability of open-source components within the Llama stack. These components are free to use and modify, which saves us money while providing high-quality tools. By leveraging these resources, we can focus on enhancing our applications instead of worrying about licensing fees.
Moreover, maintaining a project built on the Llama stack tends to be less expensive over time. The ease of updates and community support minimizes potential downtime and maintenance costs. This cost efficiency makes it an attractive choice for our ongoing projects.
Safety and Accessibility:
Safety remains a priority when using the Llama stack. We appreciate its built-in security features that protect our applications from vulnerabilities. Regular updates ensure that we stay ahead of potential threats, keeping user data safe.
Accessibility is equally important in our development process. The Llama stack promotes inclusivity by supporting various platforms and devices. This means users can access our applications regardless of their hardware or software choices. We strive to create an inclusive environment where everyone can benefit from our work.
In previous discussions about safety and accessibility, we highlighted how these elements enhance user experience. With the Llama stack, we feel empowered to develop applications that cater to diverse audiences while maintaining robust security measures.
Future Growth and Prospects for Llama 3.2:
Looking ahead, we see immense potential for growth with the Llama stack. Its evolving nature keeps us excited about new features and improvements on the horizon. Staying updated with industry trends will help us leverage these advancements effectively.
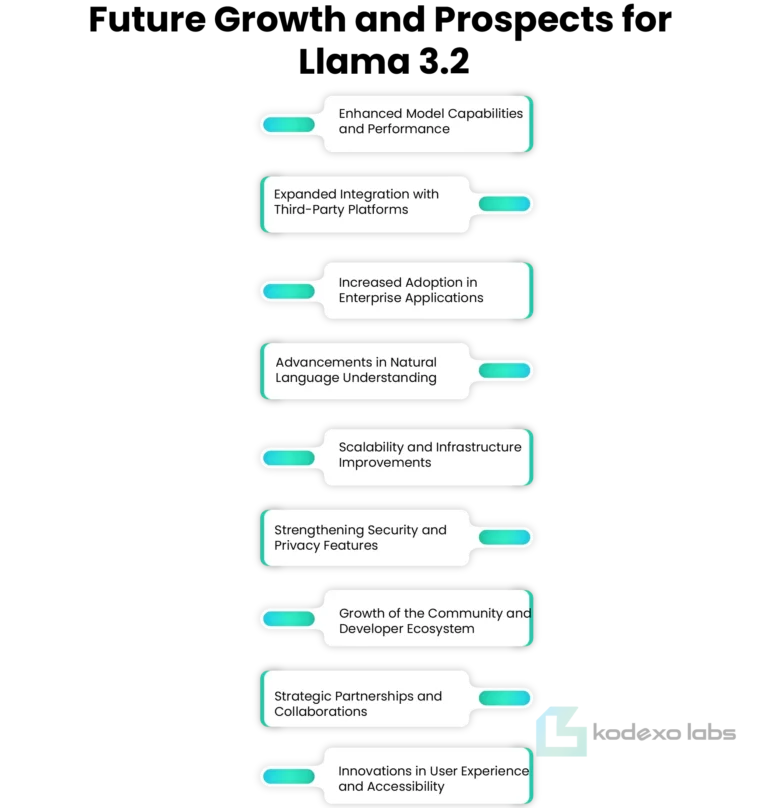
We plan to continue exploring ways to maximize our use of the Llama stack in future projects. Our goal is to remain at the forefront of technology while delivering quality applications. Embracing innovation ensures we meet user needs and stay competitive in a fast-paced market.
By investing time in mastering this technology, we position ourselves for success in upcoming endeavors. The possibilities seem endless as we navigate through challenges together.
Closing Thoughts – How to Deal with Llama 3.2
Llama 3.2 stands out in the AI landscape with its impressive features and advancements. We’ve explored its evolution, technical aspects, and how it stacks up against competitors. This model not only enhances our understanding of AI but also pushes boundaries in safety and accessibility. It’s clear that Llama 3.2 is a game-changer.
As we dive deeper into the world of AI, let’s stay curious and embrace these innovations. We invite you to explore Llama 3.2 further and see how it can elevate your projects or interests. Together, we can harness the power of this technology for a brighter future.